 AI
AI
Veel mensen hebben wel eens generatieve neurale netwerken gebruikt en gebruiken deze regelmatig, zelfs op het werk. ChatGPT en de analoge versies hiervan worden bijvoorbeeld regelmatig gebruikt door bijna 60% van de Amerikanen (en niet altijd met toestemming van het management). Alle gegevens die bij dergelijke bewerkingen betrokken zijn (zowel aanwijzingen van gebruikers als modelreacties), worden echter opgeslagen op servers van OpenAI, Google en de rest. Voor taken waarbij het lekken van dergelijke informatie onaanvaardbaar is, hoef je AI toch niet volledig achterwege te laten. Je hoeft enkel een beetje moeite (en misschien ook geld) te investeren om het neurale netwerk lokaal op je eigen computer te laten draaien – zelfs op een laptop.
Cloudbedreigingen
De populairste AI-assistenten draaien op de cloudinfrastructuur van grote bedrijven. AI-assistenten zijn snel en efficiënt, maar de gegevens die door het model worden verwerkt, zijn mogelijk toegankelijk voor zowel de AI-serviceprovider als volledig onafhankelijke partijen, zoals vorig jaar gebeurde met ChatGPT.
Dergelijke incidenten brengen verschillende dreigingsniveaus met zich mee, afhankelijk van waarvoor deze AI-assistenten worden gebruikt. Als je leuke illustraties maakt voor sprookjes die je hebt geschreven of ChatGPT vraagt een routebeschrijving te maken voor je komende stedentrip, is het onwaarschijnlijk dat een lek tot ernstige schade zal leiden. Als het gesprek met een chatbot echter vertrouwelijke informatie bevat (persoonlijke gegevens, wachtwoorden of betaalkaartnummers), is een mogelijk lek naar de cloud niet aanvaardbaar. Gelukkig is dit relatief eenvoudig te voorkomen door de gegevens vooraf te filteren. Daar hebben we een apart bericht over geschreven.
In gevallen waarin alle correspondentie echter vertrouwelijk is (bijvoorbeeld medische of financiële informatie) of de betrouwbaarheid van het filteren twijfelachtig is (je moet een grote hoeveelheid gegevens verwerken die niemand mag bekijken en filteren), is er maar één oplossing: verplaats de verwerking van de cloud naar een lokale computer. Natuurlijk is het onwaarschijnlijk dat het offline draaien van je eigen versie van ChatGPT of Midjourney succesvol zal zijn, maar andere neurale netwerken die lokaal werken, bieden vergelijkbare kwaliteit terwijl de computer minder wordt belast.
Welke hardware heb je nodig om een neuraal netwerk te laten draaien?
Je hebt waarschijnlijk gehoord dat het werken met neurale netwerken superkrachtige grafische kaarten vereist, maar in de praktijk is dit niet altijd het geval. Verschillende AI-modellen kunnen, afhankelijk van hun specifieke kenmerken, veeleisend zijn voor computeronderdelen als RAM, videogeheugen, schijf en CPU (hier is niet alleen de verwerkingssnelheid belangrijk, maar ook de ondersteuning van de processor voor bepaalde instructies van vectoren). De mogelijkheid om het model te laden is afhankelijk van de hoeveelheid RAM en de grootte van het ‘contextvenster’, oftewel het geheugen van het vorige gesprek, is afhankelijk van de hoeveelheid videogeheugen. Met een zwakke grafische kaart en CPU worden teksten erg langzaam gegenereerd (één tot twee woorden per seconde voor tekstmodellen), dus een computer met een minimale configuratie is alleen geschikt om kennis te maken met een bepaald model en om de algemene geschiktheid ervan te evalueren. Voor volwaardig dagelijks gebruik moet je de hoeveelheid RAM verhogen, de grafische kaart upgraden of een sneller AI-model kiezen.
Als uitgangspunt kan je proberen te werken met computers die in 2017 als relatief krachtig werden beschouwd: processors die niet minder krachtig zijn dan Core i7 met ondersteuning voor AVX2-instructies, 16 GB RAM en grafische kaarten met een geheugen van minimaal 4 GB. Voor Mac-liefhebbers zijn modellen die op de Apple M1-chip en hoger draaien voldoende, terwijl de geheugenvereisten hetzelfde zijn.
Wanneer je een AI-model kiest, moet je eerst vertrouwd raken met de systeemvereisten. Een zoekopdracht zoals ‘vereisten voor model_name‘ helpt je te beoordelen of het de moeite waard is om een model te downloaden, rekening houdend met je beschikbare hardware. Er zijn gedetailleerde onderzoeken beschikbaar over de impact van geheugengrootte, CPU en GPU op de prestaties van verschillende modellen; deze bijvoorbeeld.
Goed nieuws voor degenen die geen toegang hebben tot krachtige hardware: er zijn vereenvoudigde AI-modellen die zelfs op oude hardware praktische taken kunnen uitvoeren. Zelfs als je grafische kaart erg standaard en zwak is, is het mogelijk om modellen uit te voeren en omgevingen te starten met alleen de CPU. Afhankelijk van je taken kunnen deze zelfs redelijk werken.
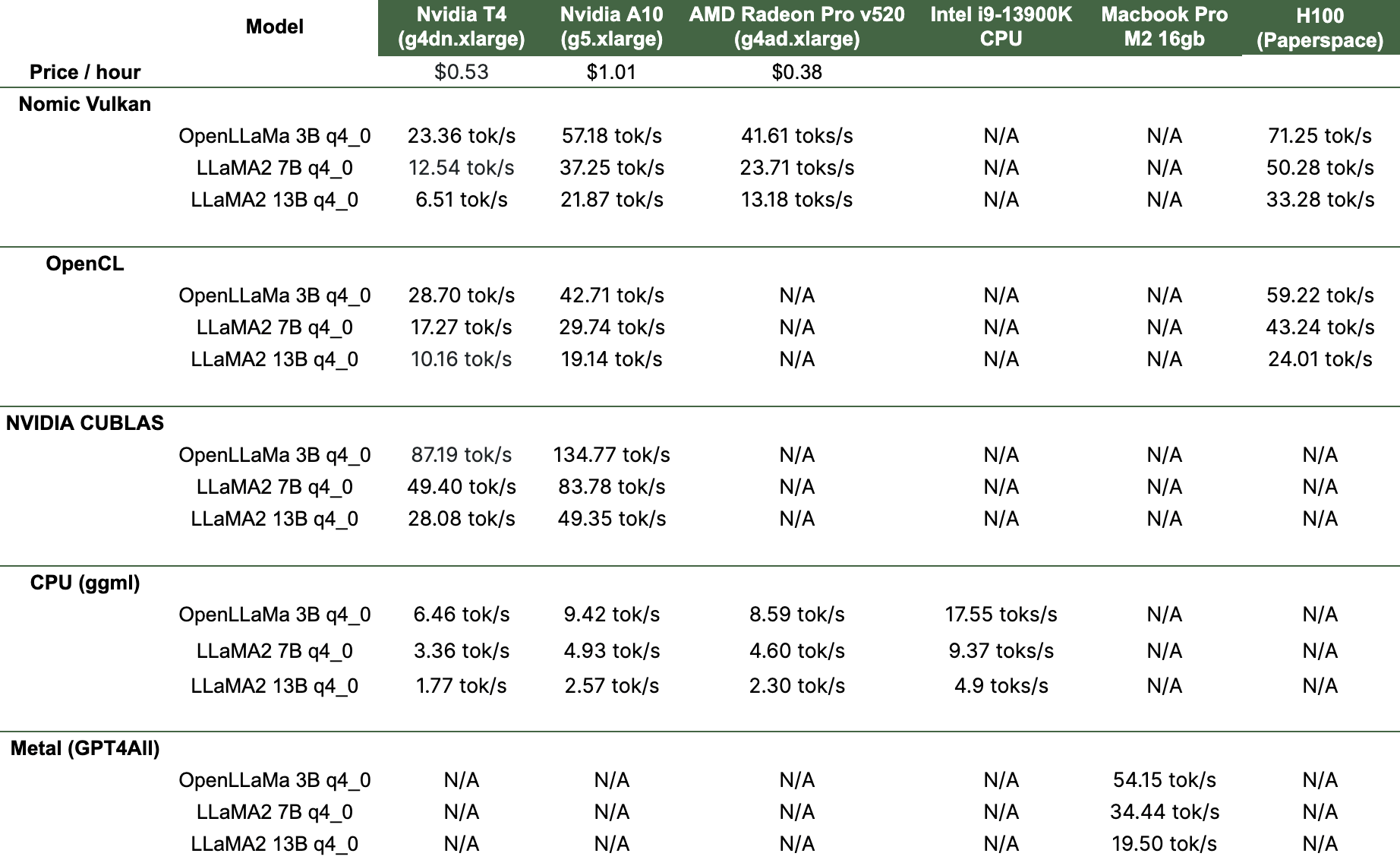
Voorbeelden van hoe verschillende computerconstructies werken met populaire taalmodellen
Kiezen voor een AI-model en de magie van kwantisatie
Er is tegenwoordig een breed scala aan taalmodellen beschikbaar, maar de meeste hebben beperkte praktische toepassingen. Toch zijn er eenvoudig te gebruiken en openbaar beschikbare AI-tools die zeer geschikt zijn voor specifieke taken, of het nu gaat om het genereren van tekst (bijvoorbeeld Mistral 7B) of het maken van codefragmenten (bijvoorbeeld Code Llama 13B). Beperk daarom bij het selecteren van een model de keuze tot een paar geschikte kandidaten en zorg er vervolgens voor dat je computer over de nodige middelen beschikt om ze uit te voeren.
In elk neurale netwerk wordt het geheugen grotendeels belast door gewichten: numerieke coëfficiënten die de werking van elk neuron in het netwerk beschrijven. In eerste instantie worden bij het trainen van het model de gewichten berekend en opgeslagen als zeer nauwkeurige fractionele getallen. Het blijkt echter dat het afronden van de gewichten in het getrainde model ervoor zorgt dat de AI-tool op gewone computers kan worden uitgevoerd, terwijl de prestaties slechts licht afnemen. Dit afrondingsproces wordt kwantisatie genoemd en met behulp van daarvan kan de grootte van het model aanzienlijk worden verkleind; in plaats van zestien bits, gebruikt elk gewicht er slechts acht, vier of zelfs twee.
Volgens huidig onderzoek kan een groter model met meer parameters en kwantisatie soms betere resultaten opleveren dan een model met nauwkeurige gewichtsopslag maar minder parameters.
Nu je dit weet, kun je een schat aan open-sourcetaalmodellen verkennen, met name het Open LLM-leaderboard. In deze lijst zijn AI-tools gesorteerd op verschillende generatiekwaliteitsstatistieken en filters die het gemakkelijk maken om modellen uit te sluiten die te groot, te klein of te nauwkeurig zijn.
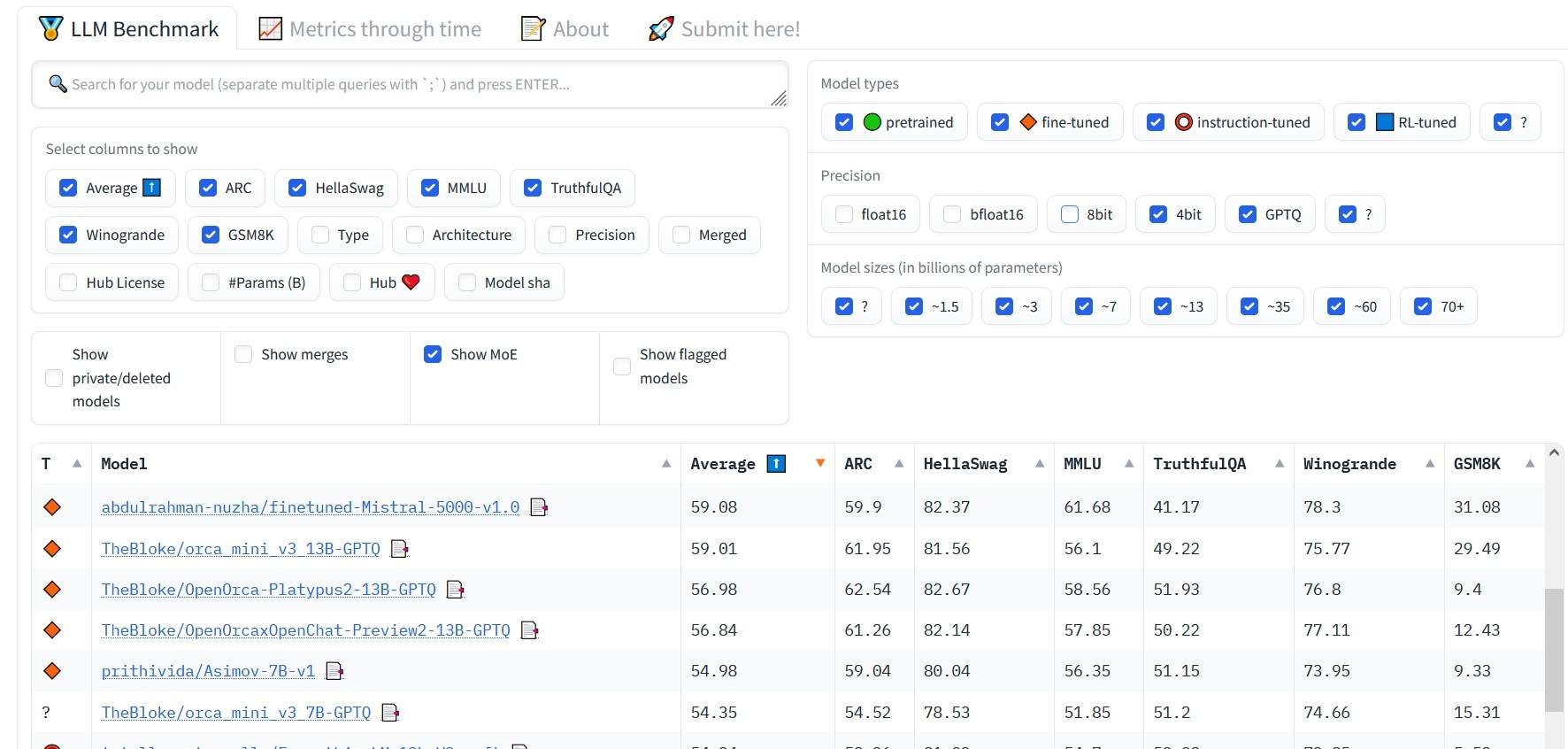
Lijst met taalmodellen gesorteerd op filter
Nadat je de beschrijving van het model hebt gelezen en er zeker van bent dat deze aan je behoeften voldoet, test je de prestaties van dit model in de cloud met behulp van de diensten van Hugging Face of Google Colab. Op deze manier voorkom je het downloaden van modellen die onbevredigende resultaten opleveren en bespaar je tijd. Zodra je tevreden bent met de eerste test van het model, is het tijd om te zien hoe het lokaal werkt!
Vereiste software
De meeste open-sourcemodellen worden gepubliceerd op Hugging Face, maar simpelweg downloaden naar je computer is niet voldoende. Om ze te laten draaien, moet je gespecialiseerde software installeren, zoals LLaMA.cpp, of, eenvoudiger zelfs, de ‘wrapper’: LM Studio. Met de tweede kun je het gewenste model rechtstreeks vanuit de applicatie selecteren, downloaden en laten draaien in een dialoogvenster.
Een andere kant-en-klare manier om een chatbot lokaal te gebruiken, is met GPT4All. Hier is de keuze beperkt tot een tiental taalmodellen, maar de meeste daarvan werken zelfs op een computer met slechts 8 GB geheugen en een eenvoudige grafische kaart.
Als er te langzaam content wordt gegenereerd, heb je mogelijk een model nodig met grovere kwantisatie (twee bits in plaats van vier). Als de generatie van content wordt onderbroken of als er uitvoeringsfouten optreden, is het probleem vaak onvoldoende geheugen. Het is de moeite waard om naar een model te zoeken met minder parameters of, wederom, met grovere kwantisatie.
Veel modellen op Hugging Face zijn al met verschillende maten van precisie gekwantiseerd, maar als niemand het gewenste model met de gewenste precisie heeft gekwantiseerd, kun je dit zelf doen met GPTQ.
Deze week werd een andere veelbelovende tool vrijgegeven als openbare bèta: Chat With RTX van NVIDIA. De fabrikant van de meest gewilde AI-chips heeft een lokale chatbot uitgebracht die de inhoud van YouTube-video’s kan samenvatten, een reeks documenten kan verwerken en nog veel meer. Dit kan echter alleen op voorwaarde dat de gebruiker een Windows-pc heeft met een geheugen van 16 GB en een grafische kaart van de 30ste of 40ste reeks van NVIDIA RTX met 8 GB of meer videogeheugen. De chatbot maakt gebruik van dezelfde varianten van Mistral en Llama 2 van Hugging Face. Natuurlijk kunnen krachtige grafische kaarten de generatieprestaties verbeteren, maar volgens de feedback van de eerste testers is de bestaande bèta behoorlijk omslachtig (ongeveer 40 GB nodig) en lastig te installeren. Chat With RTX van NVIDIA zou in de toekomst echter een zeer nuttige lokale AI-assistent kunnen worden.
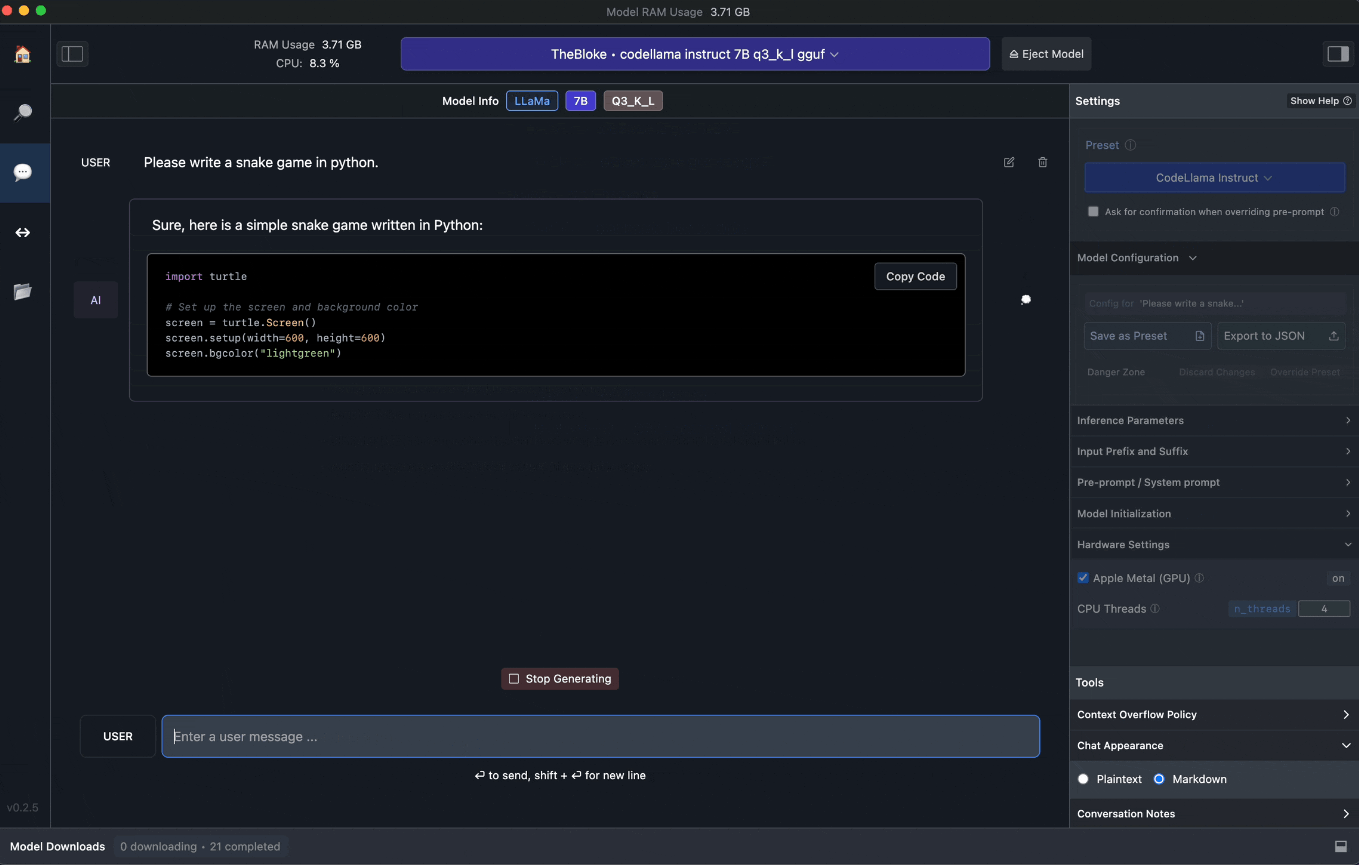
De code voor het spel ‘Snake’, geschreven door het gekwantiseerde taalmodel TheBloke/CodeLlama-7B-Instruct-GGUF
De bovengenoemde applicaties voeren lokaal alle berekeningen uit, sturen geen gegevens naar servers en kunnen offline draaien, zodat je veilig vertrouwelijke informatie met kunt delen. Om jezelf echter volledig tegen lekken te beschermen, moet je niet alleen de veiligheid van het taalmodel garanderen, maar ook die van je computer, en dat is waar onze uitgebreide beveiligingsoplossing te pas komt. Zoals bevestigd in onafhankelijke tests, heeft Kaspersky Premium vrijwel geen invloed op de prestaties van je computer, dat is een belangrijk voordeel bij het werken met lokale AI-modellen.

 Tips
Tips